---
title: Regexide
html:
offline: false
export_on_save:
html: true
toc: true
toc:
depth_from: 1
depth_to: 3
ordered: true
---

This story begins with a simple question:
!!! question How do I remove XML comments in JavaScript?
The Internet hivemind converged on one general approach: regular expressions.
The most frequently recommended answer is:
```js
str = str.replace(//g, ""); // bad, do not use
^^^^^^^^^^^^^^^^^^
```
**There are known flaws with this family of regular expressions.**
This discussion focuses on "Regexide", the act of identifying and replacing flawed regular expressions with other techniques that better reflect the intended effect.
[TOC]
## Why XML Comments matter
XML is a popular format for storing and sharing data. It was explicitly designed for people and programs to read and write data.[^1] From spreadsheets to save states, most modern software and games parse and write XML.
XML comments are special notes that parsers should not treat as data. XML comments start with ``.
Technically XML comments must not contain the string `--` within the comment body. Many programs and people write invalid XML comments, so parsers will typically allow for nested `--`.
The following XML comment is technically invalid but accepted by many parsers:
```xml
```
(Kleene wrote a seminal paper[^2] on regular expressions.)
## How the regular expression works
The regular expression body `//` has three parts:
A) `` matches the three literal characters
In (B), `[\s\S]` matches any character. The `*?` is a "non-greedy quantifier" that instructs the regular expression engine to take the shortest match.
Example of greedy and non-greedy matches (click to show)
Consider the following string:
<!-- <!-- <!-- --> --> -->
The "greedy" `//` will match from the first ``:
<!-- <!-- <!-- --> --> --> /<!--[\s\S]*-->/
The non-greedy `//` will match from the first ``:
<!-- <!-- <!-- --> --> --> /<!--[\s\S]*?-->/
` and ending with ``:
```js
const str = removeTag(value)
.replaceAll(/.*<\/del>/g, '')
// ---------^^^^^^^^^^^^^^^^^^ -- start end
```
### A rare consensus
Most resources recommend this approach.
**Books** recommend this approach. "Regular Expressions Cookbook"[^3] section 9.9 explicitly recommends `//` for matching XML comments.
**StackOverflow Answers** recommend this regular expression and variants such as `//` (which are, for all practical purposes, equivalent).
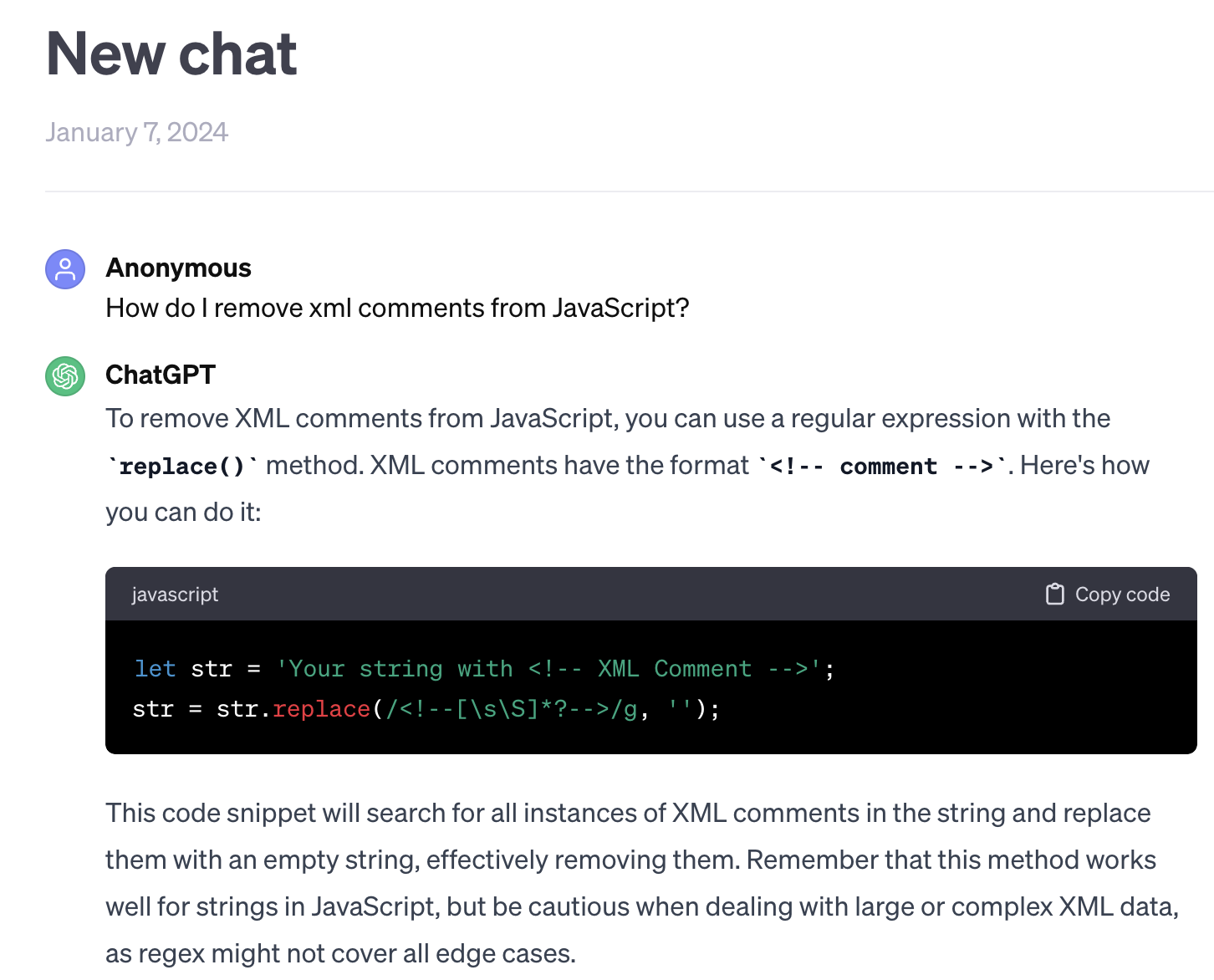
**ChatGPT4** has recommended the previous regular expression. It also generated code for a complete unrelated tag.
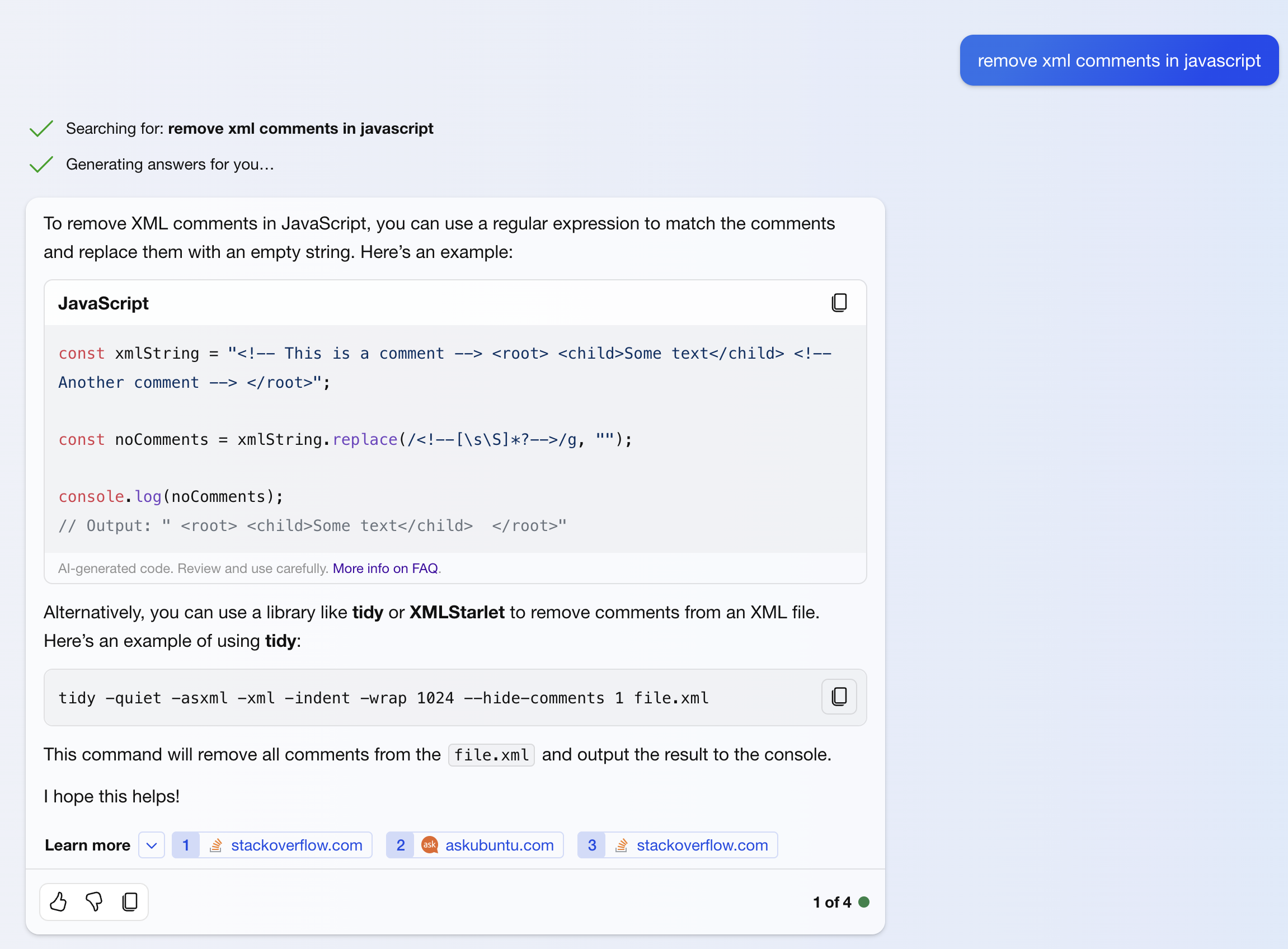
**Bing AI** proposed unrelated command line tools for JavaScript.
ChatGPT4 and Bing AI Screenshots (click to show)
_ChatGPT4 Incorrect interpretation_
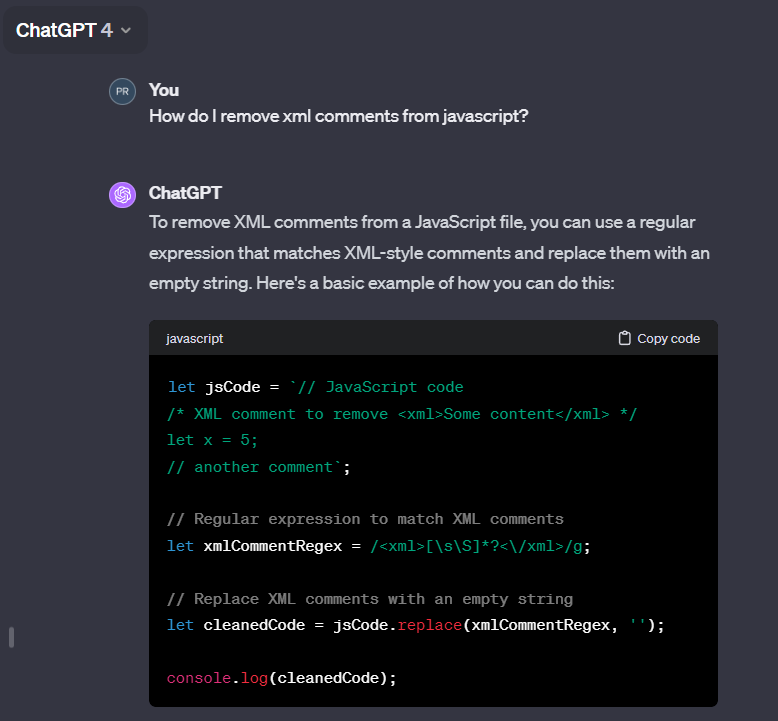
_ChatGPT4 Correct interpretation, solution uses vulnerable regular expression_
_Bing AI Correct Interpretation, solution uses vulnerable regular expression_
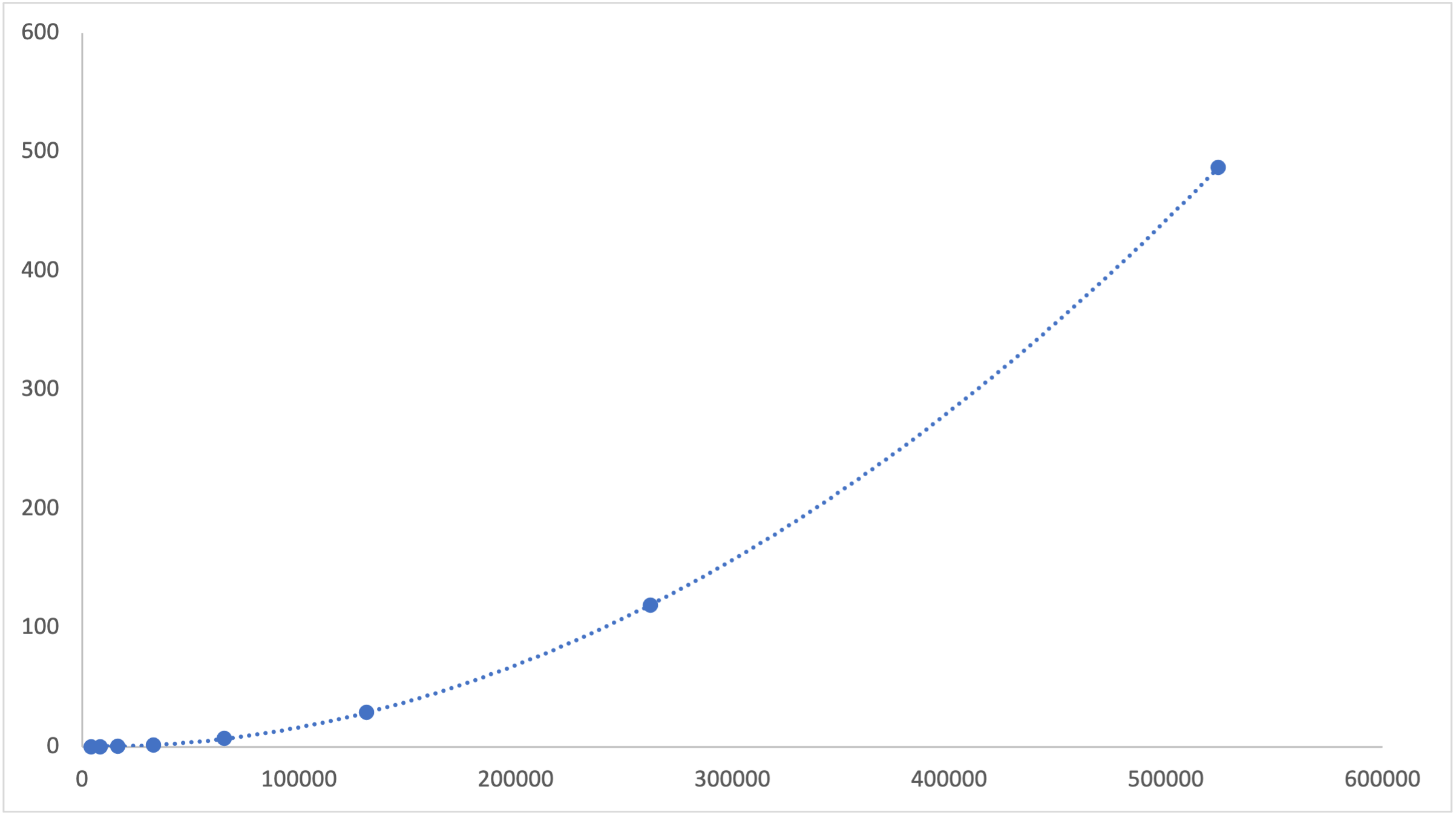 [Download the raw data as a CSV](./data/js.csv)
When the number of repetitions doubled, the runtime roughly quadrupled. This is a "quadratic" relationship.
### Why the regular expression is slow
The regular expression matches a string that starts with ``. Consider a function that repeatedly looks for the `` that appears afterwards. Computer scientists classify this algorithm as "Backtracking"[^4]:
```js {.line-numbers}
function match_all_regex_comments(str) {
const results = [];
/* look for the first instance of after ", start_index + 4);
/* if --> is found, then we have a match! */
if(end_index > -1) {
/* add to array */
results.push(str.slice(start_index, end_index + 3));
/* start scanning from the end of the `-->` */
start_index = str.indexOf("` fails (line 25 should be `break;`).
**Engines designed for JavaScript regular expressions do not currently perform this optimization.**
It can be shown that the runtime complexity of the modified algorithm is $\Theta(L+M)$ where $L$ is the string length and $M$ is the number of matches
If `-->` is not in the string, the scan `str.indexOf("-->", start_index + 4)` will look at every character in the string starting from `start_index + 4`. In the worst case, with repeated `` are highlighted in blue.
[Download the raw data as a CSV](./data/js.csv)
When the number of repetitions doubled, the runtime roughly quadrupled. This is a "quadratic" relationship.
### Why the regular expression is slow
The regular expression matches a string that starts with ``. Consider a function that repeatedly looks for the `` that appears afterwards. Computer scientists classify this algorithm as "Backtracking"[^4]:
```js {.line-numbers}
function match_all_regex_comments(str) {
const results = [];
/* look for the first instance of after ", start_index + 4);
/* if --> is found, then we have a match! */
if(end_index > -1) {
/* add to array */
results.push(str.slice(start_index, end_index + 3));
/* start scanning from the end of the `-->` */
start_index = str.indexOf("` fails (line 25 should be `break;`).
**Engines designed for JavaScript regular expressions do not currently perform this optimization.**
It can be shown that the runtime complexity of the modified algorithm is $\Theta(L+M)$ where $L$ is the string length and $M$ is the number of matches
If `-->` is not in the string, the scan `str.indexOf("-->", start_index + 4)` will look at every character in the string starting from `start_index + 4`. In the worst case, with repeated `` are highlighted in blue.
<!--<!--<!--<!--<!--
^^^^ (first match of <!-- 0 - 3)
............ (scan for --> from index 4 to end) L - 4 characters
<!--<!--<!--<!--<!--
^^^^ (second match of <!-- 4 - 7)
........ (scan for --> from index 8 to end) L - 8 characters
<!--<!--<!--<!--<!--
^^^^ (third match of <!-- 8 - 11)
.... (scan for --> from index 12 to end) L - 12 characters
For $N$ repetitions of `").unwrap();
let mut str = "").unwrap();
/* construct string by repeating with itself */
let mut str = "/mg),""); // replace
```
Complete Example (click to show)
```js
var RE2 = require("re2");
// this loop doubles each time
for(var n = 64; n < 100000000; n*=2) {
var s = "/mg),""); // replace
console.timeEnd(n);
}
```
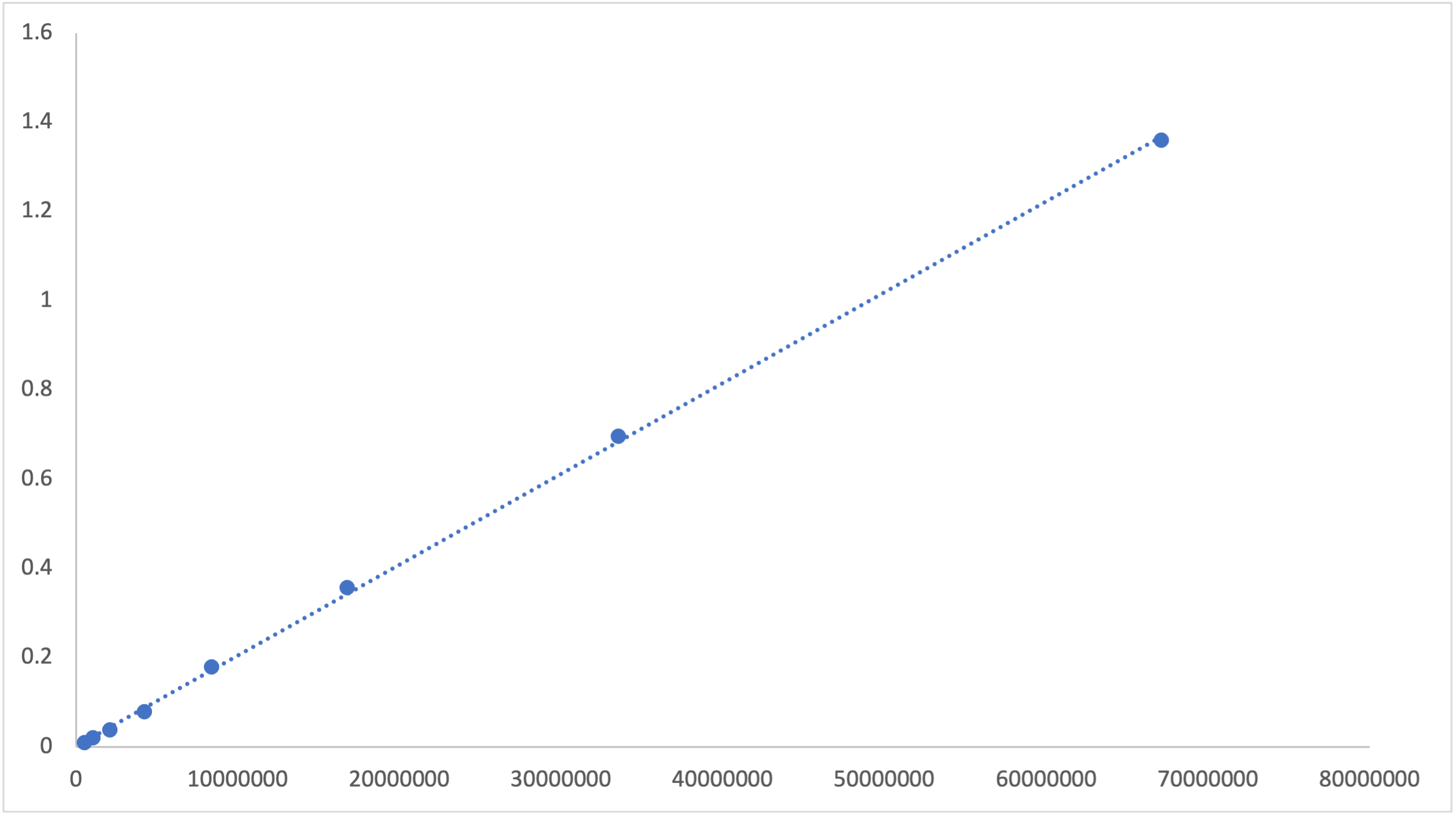 [Download the raw data as a CSV](./data/re2.csv)
#### Rust
The Rust `regex`[^9] crate sacrifices support for performance. It is the same tradeoff made by the `re2` engine.
Since it does not use lookaround or backreferences, the original regular expression is compatible with the `regex` crate:
```rust
let re = regex::Regex::new(r"").unwrap();
let mut str = "").unwrap();
/* construct string by repeating with itself */
let mut str = "
```
[PrettierJS](https://github.com/prettier/prettier/blob/ff83d55d05e92ceef10ec0cb1c0272ab894a00a0/src/language-markdown/mdx.js#L28) uses a regular expression in the MDX parser that enforces the XML constraint:
```js
const COMMENT_REGEX = /|/;
```
Commonly-used regular expression engines can optimize for this pattern and avoid backtracking.
!!! info Spreadsheet Engines
The XML parser in Excel powering the [Excel Workbook (XLSX) format](https://docs.sheetjs.com/docs/miscellany/formats/#excel-2007-xml-xlsxxlsm) expects proper XML comments with no `--` in the comment body.
The XML parser in Excel powering the [Excel 2003-2004 (SpreadsheetML) format](https://docs.sheetjs.com/docs/miscellany/formats#excel-2003-2004-spreadsheetml) allows `--` in the comment body.
#### HTML Comments
The HTML5 standard[^11] permits `--` but forbids `', '', html)
```
This expression allows `--` but disallows `` are treated as a comment. For example, consider the following HTML:
```html
[Download the raw data as a CSV](./data/re2.csv)
#### Rust
The Rust `regex`[^9] crate sacrifices support for performance. It is the same tradeoff made by the `re2` engine.
Since it does not use lookaround or backreferences, the original regular expression is compatible with the `regex` crate:
```rust
let re = regex::Regex::new(r"").unwrap();
let mut str = "").unwrap();
/* construct string by repeating with itself */
let mut str = "
```
[PrettierJS](https://github.com/prettier/prettier/blob/ff83d55d05e92ceef10ec0cb1c0272ab894a00a0/src/language-markdown/mdx.js#L28) uses a regular expression in the MDX parser that enforces the XML constraint:
```js
const COMMENT_REGEX = /|/;
```
Commonly-used regular expression engines can optimize for this pattern and avoid backtracking.
!!! info Spreadsheet Engines
The XML parser in Excel powering the [Excel Workbook (XLSX) format](https://docs.sheetjs.com/docs/miscellany/formats/#excel-2007-xml-xlsxxlsm) expects proper XML comments with no `--` in the comment body.
The XML parser in Excel powering the [Excel 2003-2004 (SpreadsheetML) format](https://docs.sheetjs.com/docs/miscellany/formats#excel-2003-2004-spreadsheetml) allows `--` in the comment body.
#### HTML Comments
The HTML5 standard[^11] permits `--` but forbids `', '', html)
```
This expression allows `--` but disallows `` are treated as a comment. For example, consider the following HTML:
```html
--> more text
| |^^^^^^^^^^^^^^ --- content
| this is interpreted as a comment |
```
This exact HTML code is added below:
--> more text
Chromium and other browsers will display `--> more text`
### Remove the Regular Expression
Regular expression operations can be reimplemented using standard string operations.
For example, the replacement
```js
str = str.replace(//, "");
```
can be rewritten with a loop. The core idea is to collect non-commented fragments:
```js {.line-numbers}
function remove_xml_comments(str) {
const START = "";
const results = [];
/* this index tracks the last analyzed character */
let last_index = 0;
/* look for the first instance of after is found, then we have a match! */
if(end_index > -1) {
/* skip the comment */
last_index = end_index + END.length;
/* search for next comment open tag */
start_index = str.indexOf(START, last_index);
}
/* if there is no end comment tag, stop processing */
else break;
}
/* add remaining part of string */
results.push(str.slice(last_index));
/* concatenate the fragments */
return results.join("");
}
```
### Validate Data
In the places where ViteJS used the vulnerable regular expression, the text was validated using a separate HTML parser.
It is still strongly recommended to replace the regular expression.
### Limit to Trusted Data
PrettierJS and RollupJS use the vulnerable regular expression in internal scripts. The expressions are not used or added in websites. The data sources are trusted and malformed data can be corrected manually.
## Special Thanks
Special thanks to [Asadbek](https://asadbek.dev/), [Jardel](http://francoatmega.com/), and members of the [SheetJS team](https://sheetjs.com) for early feedback.
[^1]: See ["Origin and Goals"](https://www.w3.org/TR/REC-xml/#sec-origin-goals) in the Extensible Markup Language (XML) 1.0 specification.
[^2]: The theoretical underpinnings of modern regular expressions were established in the working paper ["Representation of Events in Nerve Nets and Finite Automata"](https://www.rand.org/content/dam/rand/pubs/research_memoranda/2008/RM704.pdf)
[^3]: See ["9.9 Remove XML-Style Comments"](https://www.oreilly.com/library/view/regular-expressions-cookbook/9781449327453/ch09s10.html) on the official site for the book.
[^4]: See [the Wikipedia article for "Backtracking"](https://en.wikipedia.org/wiki/Backtracking) for more details and resources.
[^5]: See [the definition in the "CWE List"](https://cwe.mitre.org/data/definitions/1333.html) for more details and resources.
[^6]: See [the listing for `regress` crate](https://crates.io/crates/regress) for more details.
[^7]: See [the `google/re2` project on GitHub](https://github.com/google/re2) for more details.
[^8]: See [the listing for the `re2` NodeJS package](https://www.npmjs.com/package/re2) for more details.
[^9]: See [the listing for `regex` crate](https://crates.io/crates/regex) for more details.
[^10]: See ["Comments"](https://www.w3.org/TR/REC-xml/#sec-comments) in the XML 1.0 specification.
[^11]: See ["Comments"](https://html.spec.whatwg.org/multipage/syntax.html#comments) in the WHATWG HTML Living Standard.