Encoding issue when convertting slk file to csv #1544
Labels
No Label
DBF
Dates
Defined Names
Features
Formula
HTML
Images
Infrastructure
Integration
International
ODS
Operations
Performance
PivotTables
Pro
Protection
Read Bug
SSF
SYLK
Style
Write Bug
good first issue
No Milestone
No Assignees
1 Participants
Notifications
Due Date
No due date set.
Dependencies
No dependencies set.
Reference: sheetjs/sheetjs#1544
Loading…
Reference in New Issue
Block a user
No description provided.
Delete Branch "%!s()"
Deleting a branch is permanent. Although the deleted branch may continue to exist for a short time before it actually gets removed, it CANNOT be undone in most cases. Continue?
Hello,
I'm trying to convert a slk file to csv file, with the code see below :
Here a link for the slk sample file
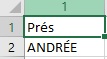
When I'm opening the source file with Excel the result is :
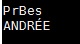
The result on the console or csv file is :
Could you please tell me if I'm doing something wrong ?
Thanks in advance.
The file uses some sort of 7-bit escape sequence (like VT-52). The hexadecimal byte representations, with a CP1252 interpretation replacing the ascii ESC with _, look like this:
You don't see the
Nin the console because0x1b 0x4eis interpreted as an escape sequence.Excel 2019 seems to prefer using those, since opening and saving the file actually rewrites cell A2 to use a similar scheme:
We would have to go back and either brute-force the characters Excel uses in CHAR function or try to find old documentation. Do you have any other characters in mind?
Thanks for your reply, it's most clear for me :)
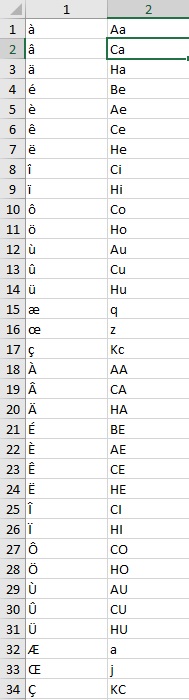
I wrote the list of the french accent and I updated my code with :
Could you please tell me if it's a «clean» way ?
Ultimately this logic will be pushed into the slk parser.
There seem to be two different sets of patterns involved. In addition to the
\u001BNencoding, there is another two-character encoding like\u001B 9(ESC SPC 9) which maps to the tab character! That second one is a bit more regular: the first character encodes the high 4 bits (starting at SPC which has ASCII code0x20) and the second character encodes the low 4 bits (starting at "0" which has ASCII code0x30). Interestingly there are two valid encodings ofŒ:\u001BNjand\u001B(<. We'll do a bit more digging to see if there's an actual pattern in the\001BNcase.PS: in your regular expression the first group is not necessary:
If you wanted to go even further, you could programmatically generate the regexp:
Thanks a lot for your help ;)